Monitoring student safety during generative chats
I’ve previously written about my work with Rori designing educational and useful generative chat experiences for math students. We’ve launched a number of generative chats and initial results are promising (check out the workshop paper we presented at EDM 2024). Here, I want to summarize our approach to monitoring student safety during generative chats.
Our key intuition about student safety during generative chats is that we can adapt behavior management techniques used in 1-on-1 tutoring sessions. Automated systems must define their behavior management approach ahead of time, which already has a more general name: automated content moderation.
By thinking of study safety as a content moderation problem, we can focus on the moderation actions that we want the system to take in response to specific student messages.
 Flowchart: how we process student messages during generative chats
Flowchart: how we process student messages during generative chats
The safety filter we use has two parts: a filtered word list and a statistical estimate of inappropriate content as provided by the OpenAI moderation API.
Let’s leave aside the fraught question of whether these categories are appropriate for sufficient for all educational contexts, and look at how OpenAI defines the categories:
| Category | Description |
|---|---|
| hate | Content that expresses, incites, or promotes hate based on race, gender, ethnicity, religion, nationality, sexual orientation, disability status, or caste. Hateful content aimed at non-protected groups (e.g., chess players) is harassment. |
| hate/threatening | Hateful content that also includes violence or serious harm towards the targeted group based on race, gender, ethnicity, religion, nationality, sexual orientation, disability status, or caste. |
| harassment | Content that expresses, incites, or promotes harassing language towards any target. |
| harassment/threatening | Harassment content that also includes violence or serious harm towards any target. |
| self-harm | Content that promotes, encourages, or depicts acts of self-harm, such as suicide, cutting, and eating disorders. |
| self-harm/intent | Content where the speaker expresses that they are engaging or intend to engage in acts of self-harm, such as suicide, cutting, and eating disorders. |
| self-harm/instructions | Content that encourages performing acts of self-harm, such as suicide, cutting, and eating disorders, or that gives instructions or advice on how to commit such acts. |
| sexual | Content meant to arouse sexual excitement, such as the description of sexual activity, or that promotes sexual services (excluding sex education and wellness). |
| sexual/minors | Sexual content that includes an individual who is under 18 years old. |
| violence | Content that depicts death, violence, or physical injury. |
| violence/graphic | Content that depicts death, violence, or physical injury in graphic detail. |
Per the docs, the scores returned by the API indicate “the model’s confidence that the input violates OpenAI’s policy for the category. The value is between 0 and 1, where higher values denote higher confidence. The scores should not be interpreted as probabilities.”
We use the scores to determine which moderation action to take based on a per-category threshold, calibrated based on the data we’ve collected so far. How do we do that? By looking at student messages deemed harmful by the API.
I implemented a dashboard (in Streamlit) to visualize the disallowed words and the number of messages within some time period that are flagged at our current threshold setting.
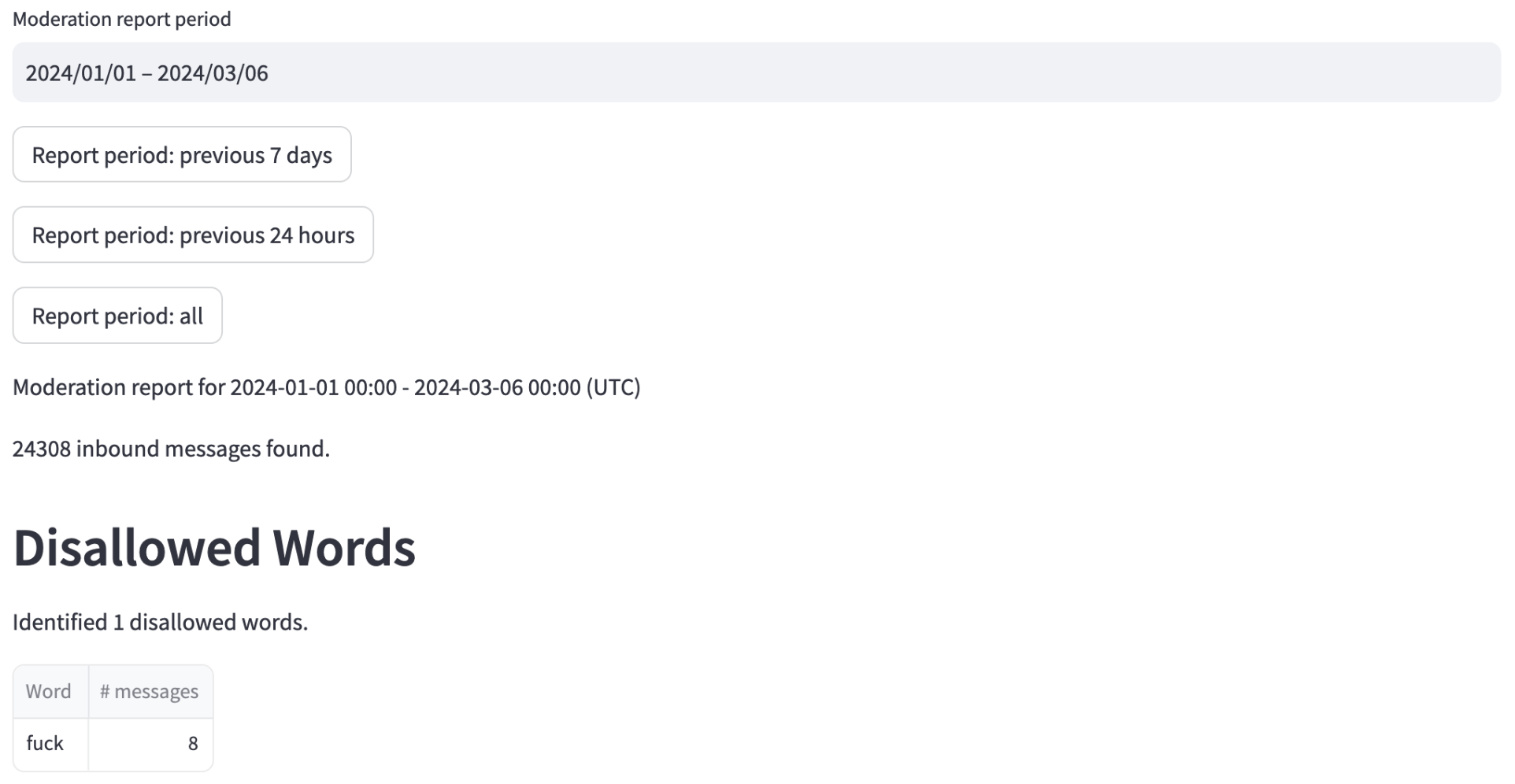 Moderation safety report: implemented as a Streamlit dashboard
Moderation safety report: implemented as a Streamlit dashboard
 OpenAI moderation score summary table
OpenAI moderation score summary table
For each category, we show a histogram of student message scores.
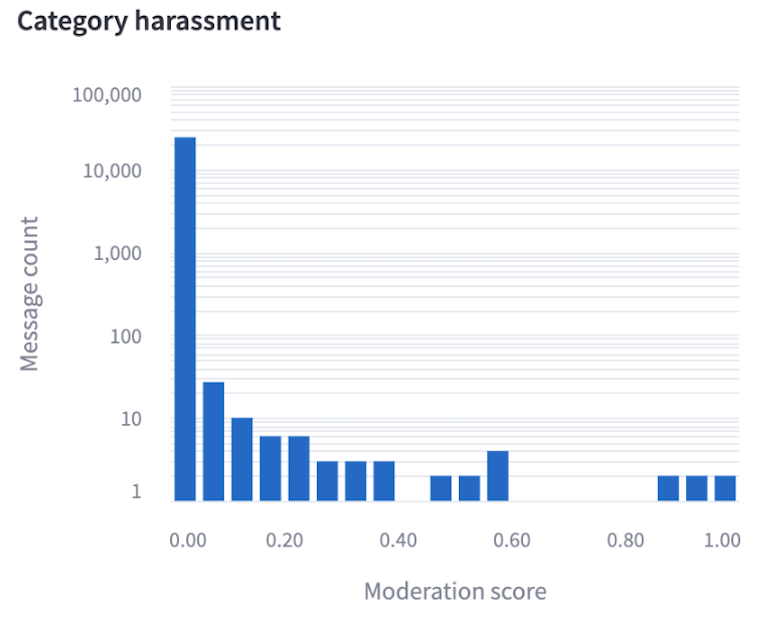
In addition, we show the highest-scoring messages. We monitor all messages above the threshold to determine if additional real-world follow-up action is required.
One of the main use cases for this dashboard is to determine if the thresholds we’re using is appropriate. To assist in making that assessment, we also show the six messages closest to the moderation threshold: three that were flagged as just over the threshold and three that were unflagged as just below the threshold. These messages provide a quick-to-evaluate and intuitive sense of whether this threshold is producing lots of false negatives or false positives.
OpenAI specifically expects you to do recalibration if you threshold on the raw scores, due to changes in the underlying model. We use this dashboard to conduct that recalibration.