An interesting two envelopes problem
Shared by Leonardo Cotta on Twitter:
I find it interesting that people often don’t know this riddle, but it tells you everything you need to know about randomized algorithms ;)
I have never studied randomized algorithms, and I found the problem and its solution very interesting.
The problem:
Consider two envelopes labeled A and B, each containing a real number. You’re allowed to select one envelope and view its value before deciding whether A or B has the max value. Can you devise a strategy to decide the max envelope with a probability greater than 0.5?
The solution:
1) Pick your favourite distribution with support over R, e.g. Gaussian.
2) Pick a random number X according to this distribution.
3) You pick one envelope uniformly at random and see the value Y.
4) You switch if X > Y and keep your envelope if X <= Y.
What is your success probability? If X > max(A,B), your algorithm picks an envelope unif at random (because you pick one at random, and always switch, which is equivalent to pick one unif at random). If X <= min(A,B), your algorithm picks an envelope at random (same reason). If min(A,B) < X < max(A,B) you are always correct!
So your success probability is 0.5 + Pr[min(A,B) < X < max(A,B)] > 0.5.
I don’t know if this problem or class of problems has a name. Intuitively, it seems related to the two envelopes problem.
Edit September 2024: Thanks to Vince Buffalo on Twitter for pointing to two sources on this problem:
- Theodore Hill writes about the problem in “Knowing When to Stop: How to gamble if you must—the mathematics of optimal stopping” [pdf] (American Scientist, 2009). Hill points out that this problem is the n=2 case of the secretary problem.
- Pradeep Mutalik writes about the problem in “Solution: ‘Information From Randomness?’” (Quanta Magazine, July 2015). Mutalik observes that Thomas Cover published a solution to this problem in 1987.
Simulating the max two envelope problem
Does the strategy described above actually work? Let’s try simulating this strategy on fake data so we can convince ourselves it will work. (I’m a fan of simulations for estimating probabilities when we’re not confident in our ability to compute the probabilties analytically.)
In the real problem, we don’t get to know the distribution from which the envelope values are drawn. For my simulation, I’ll just take draws from the standard normal distribution.
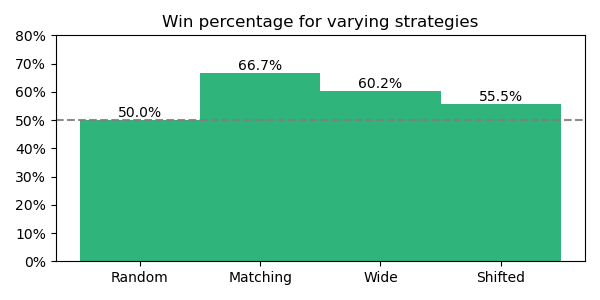 Over 10 million envelope openings, the strategy described above produces above-chance success probability.
Over 10 million envelope openings, the strategy described above produces above-chance success probability.
If I draw my “decision value” (X) from the same (matching) distribution, I increase my success probability from 50% to 66%. (That implies Pr[min(A,B) < X < max(A,B)] ≈ 0.166 when A, B, and X are drawn from the standard normal distribution.) If the distribution I choose has a higher standard deviation (wide), my success probability will drop correspondingly (but still be above chance). Similarly, if I shift the distribution’s mean (shifted) so that fewer decision values lie between A and B, my success probability will also drop. As described in the proof above, it’s all about how likely it is that X falls between A and B.
The code for this simulation is on GitHub.