Research paper: TnT-LLM
In “TnT-LLM: Text Mining at Scale with Large Language Models”, Wan et al. propose a two-step process for developing text classifiers for vaguely-defined tasks.
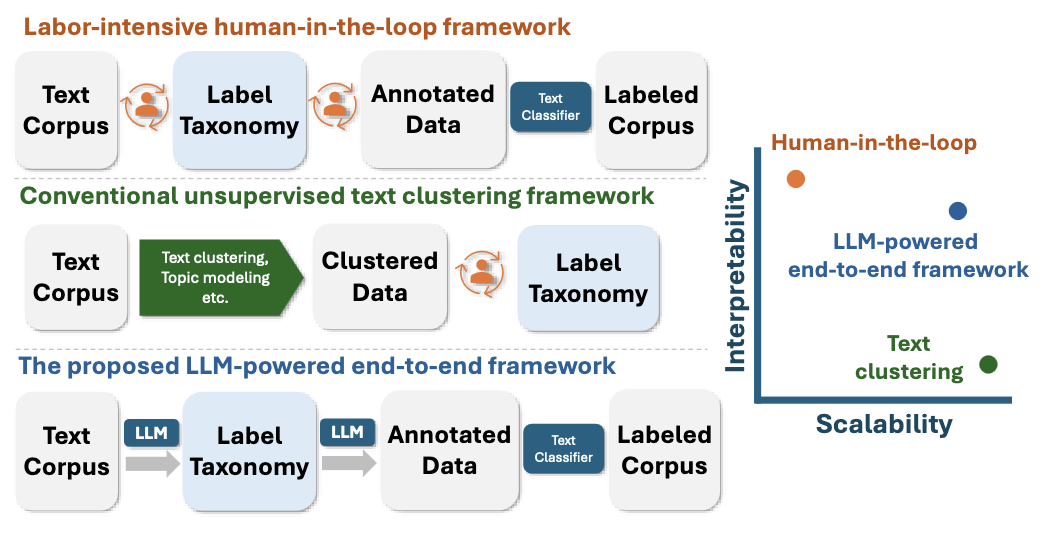 Figure 1 from the TnT-LLM paper.
Figure 1 from the TnT-LLM paper.
They define taxonomy generation as “finding and organizing a set of structured, canonical labels that describe aspects of the corpus”.
Handcrafted taxonomies, beyond being expensive to construct, tend to be developed for specific downstream tasks (e.g., web search intent analysis, chatbot intent detection), or tied to the development of specific datasets. Automated approaches scale better but either rely on term extraction from corpora to obtain labels, which may hinder interpretability and/or coverage, or else require a set of seeds for the taxonomy in order to generate new labels.
I’m a known hater of automated approaches to taxonomy generation. (Topic modeling wins my personal “most misused method” award.) I published “Bridging Qualitative and Quantitative Methods for User Modeling” on the problem of building text classifiers from taxonomies derived from qualitative work. So the idea of using LLMs to assist in the production of taxonomies is an intriguing one.
Here’s Wan et al.’s interesting claim: “TnT-LLM treats taxonomy generation and text classification as interrelated problems in an end-to-end pipeline, whereas prior work has tended to focus mainly on the quality of the taxonomy produced, without considering its downstream utility for classification.”
I won’t describe their actual approach, but the basic idea is reasonable. Unfortunately, there is little evidence in the paper for the utility or coherence of the label taxonomy produced. (It seems like it would be easy to fool oneself; even if the individual labels are reasonable, the task structure may not be.)
I would be interested in a semi-automated approach in which the label taxonomy generation puts a human in the loop to refine label categories and inspect the coherence and relevance of each label category. From that perspective, “LLMs as annotators” bears resemblance to guided topic modeling approaches, where iterative inspection of documents and document labels is combined with explicit guidance (such as merging, splitting, adding, or deleting categories).