Skrub
Skrub is an amazing library being developed by Patricio Cerda, Gaël Varoquaux, and Balázs Kégl, among other contributors.
I used its functionality recently to save myself after a serious data screw-up. I wrote a script that produced a Qualtrics survey for a bunch of individual texts, but I lost the IDs that would enable me to match survey responses back to my original dataset. With Skrub, I was able to execute a fuzzy join, joining the datasets directly on the texts even though they were formatted differently (markdown vs HTML).
The miracle merge (in this notebook):
joined_df = skrub.fuzzy_join(
df,
survey_df,
on="text",
return_score=True,
suffixes=("", "_survey"),
)
Notice the return_score parameter, which results in confidence scores based on the degree of text overlap.
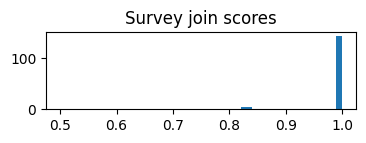
143 were considered to be “perfect” matches, and I manually inspected the remaining 10 to verify they had been matched correctly.
The next time you find yourself with two messy but related datasets that could be joined on a text column if only they were normalized, try Skrub!